准备工作
- 服务器或者电脑一台,配置越高越好, Windows和Mac皆可,Widows最好内存8G以上而且带一块好一点的显卡;Mac的话建议M系列芯片,内存建议16G以上(咕咕用的是Apple M1 Max 64G版)
- 下载好docker桌面版
- 下载好Ollama
注意:运行 7B 模型时,您应至少有 8 GB 的可用内存,运行 13B 模型时应有 16 GB 的可用内存,运行 33B 模型时应有 32 GB 的可用内存。
M系列MacBook采用统一内存架构,这意味着CPU和GPU可以共享同一内存池。这种设计减少了数据在不同处理单元之间传输的需要,从而可以显著提高大型数据集处理的速度和效率。
下载Ollama

其实这个也可以用docker来装,但是既然给了安装版,我们就直接到官网下载即可。
什么是Ollama?

Ollama 是一个便于本地部署和运行大型语言模型(Large Language Models, LLMs)的工具。使用通俗的语言来说,如果你想在自己的电脑上运行如 GPT-3 这样的大型人工智能模型,而不是通过互联网连接到它们,那么 Ollama 是一个实现这一目标的工具。
Ollama支持非常多的开源模型,比如:
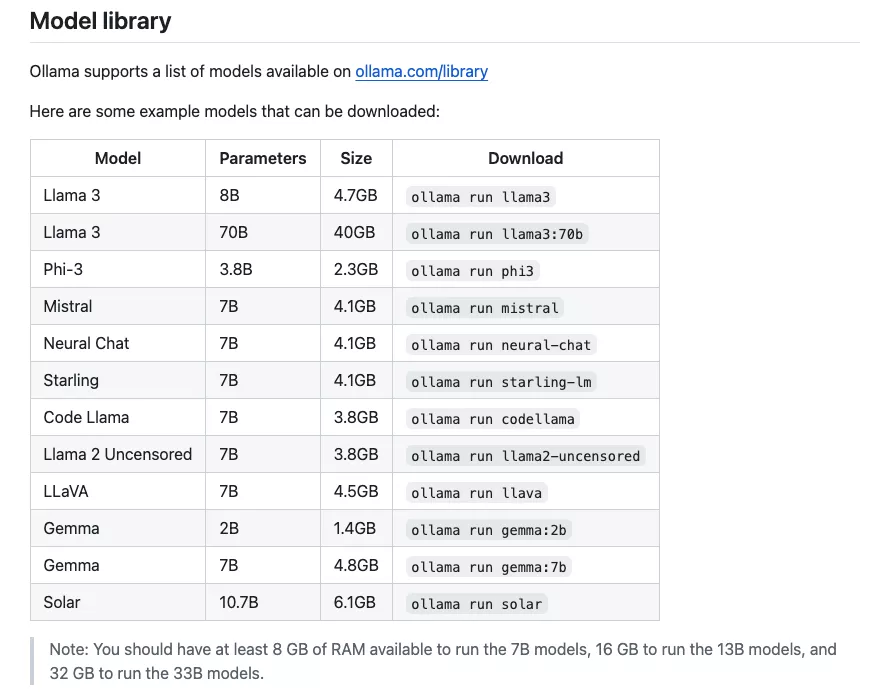
更多支持的模型可以看这边:https://ollama.com/library
当然它还支持自定义模型,这边就不深入了,有兴趣的可以研究:https://github.com/ollama/ollama
装好之后,命令行运行:
ollama -v查看到版本号说明安装好了。
接下来我们下载一个llama3 8B的模型:
ollama run llama3这边可能需要比较长的时间,取决于你的网速。
下载好了就可以进行交互了:
/? 可以查看帮助:
/bye 可以退出

其实现在已经搞定了,你可以让它帮你干活了,但是每次都要用命令行,有些人觉得不方便,而且也不能给别人用,下面我们就给它搞一个图形化界面,扩展一下功能,也能让局域网里的其他小伙伴也用上你的这个模型(注意多人同时访问会导致机器负载飙升,具体取决于你机器的性能和模型参数的大小)
搭建LobeChat
下面给出docker-compose.yaml的文件,大家可以用之前学习过的docker知识参考搭建。(不清楚的可以找一篇之前的项目文章,去B站看一下docker项目怎么跑的,一看就懂了,很简单)
services:
lobe-chat:
image: lobehub/lobe-chat
container_name: lobe-chat
restart: always
ports:
- '11432:3210'
environment:
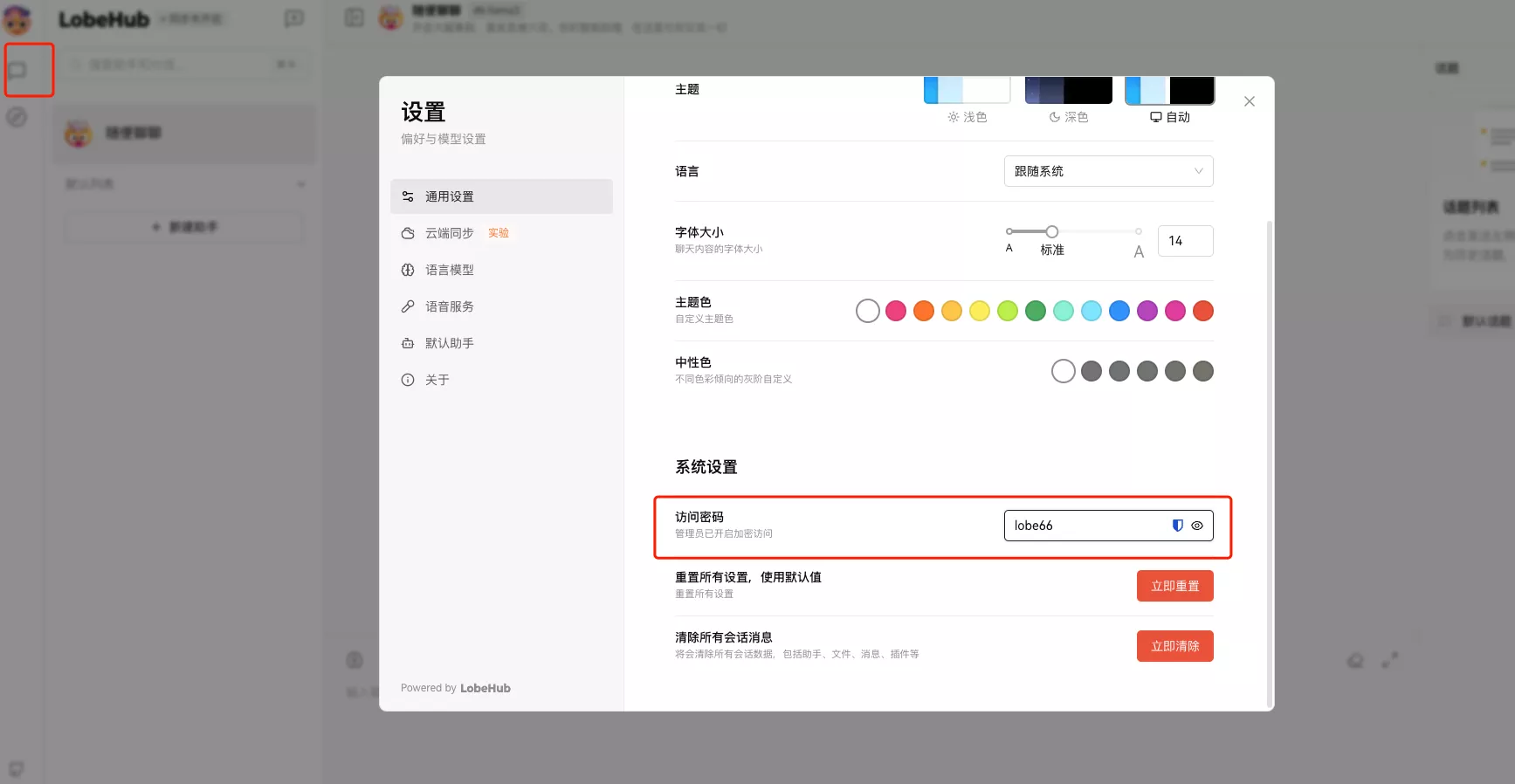
ACCESS_CODE: lobe66
OLLAMA_PROXY_URL: http://host.docker.internal:11434/v1
本地装好docker,可以去docker官网直接下载一个安装包。
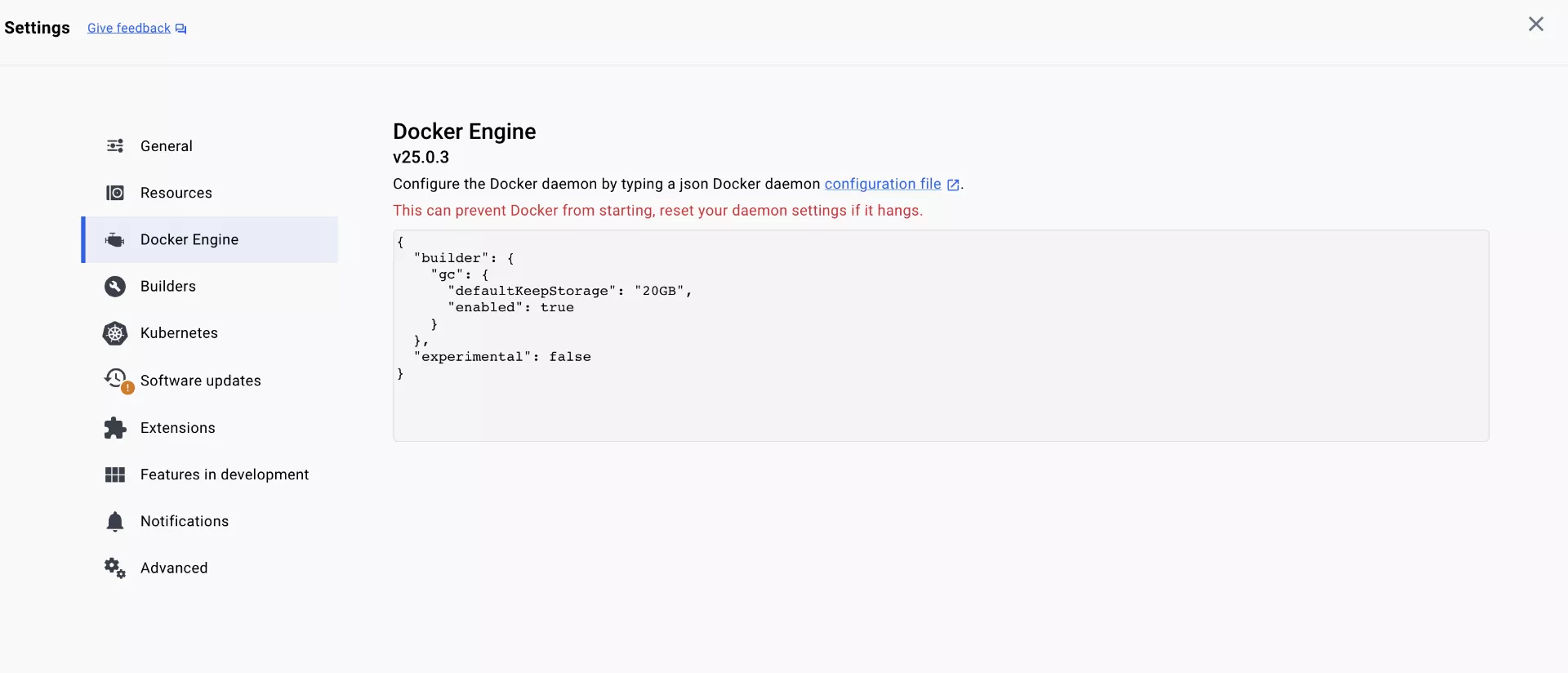
同样的,输入docker -v,有版本号说明安装好了。

这边还会涉及docker换源,由于防火墙的原因,我们大陆可能无法访问docker的镜像仓库,建议大家换成中科大的源:https://docker.mirrors.ustc.edu.cn/
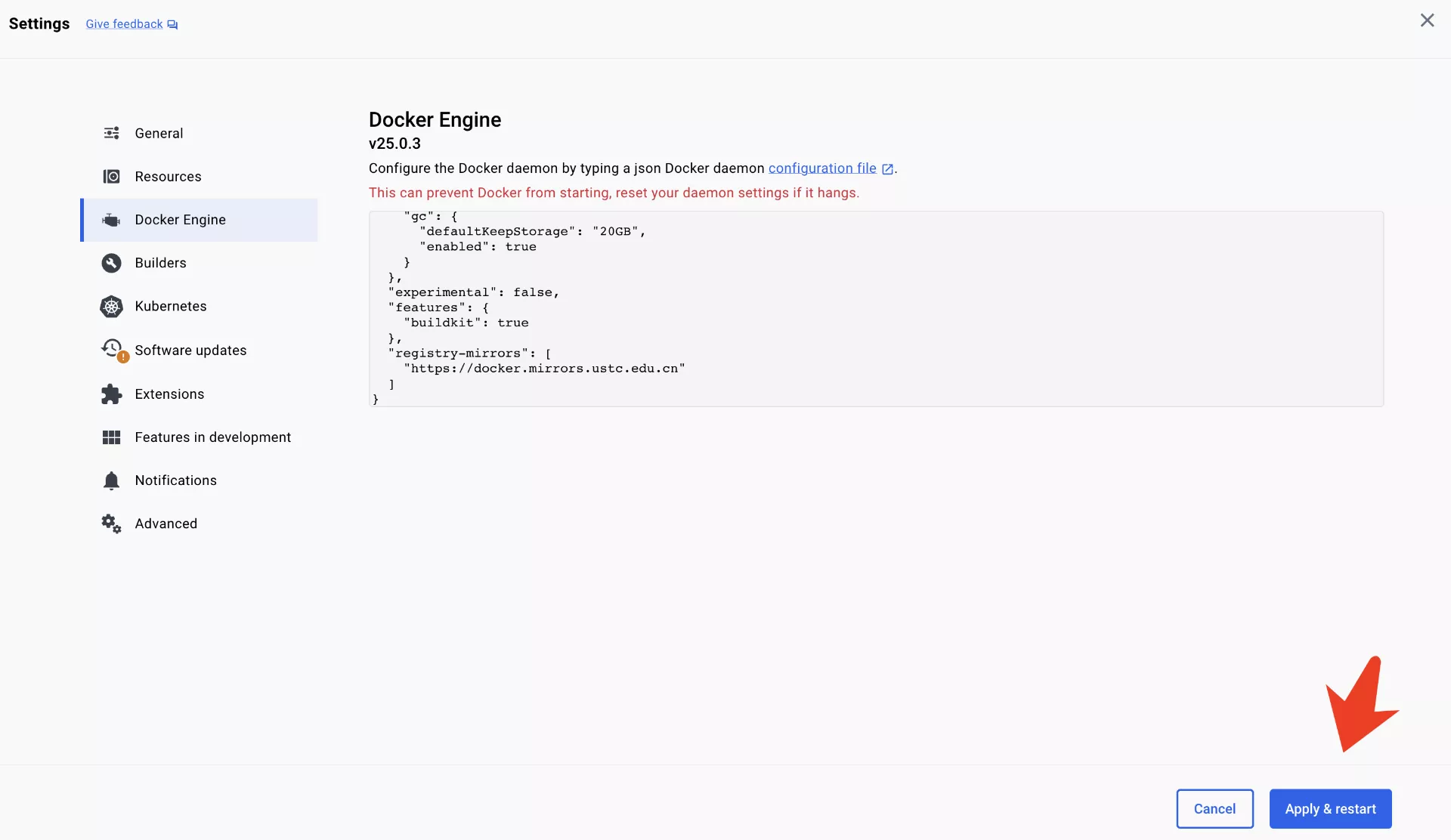
改成这个:
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"features": {
"buildkit": true
},
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn"
]
}
使用如下命令查看Docker配置
docker info
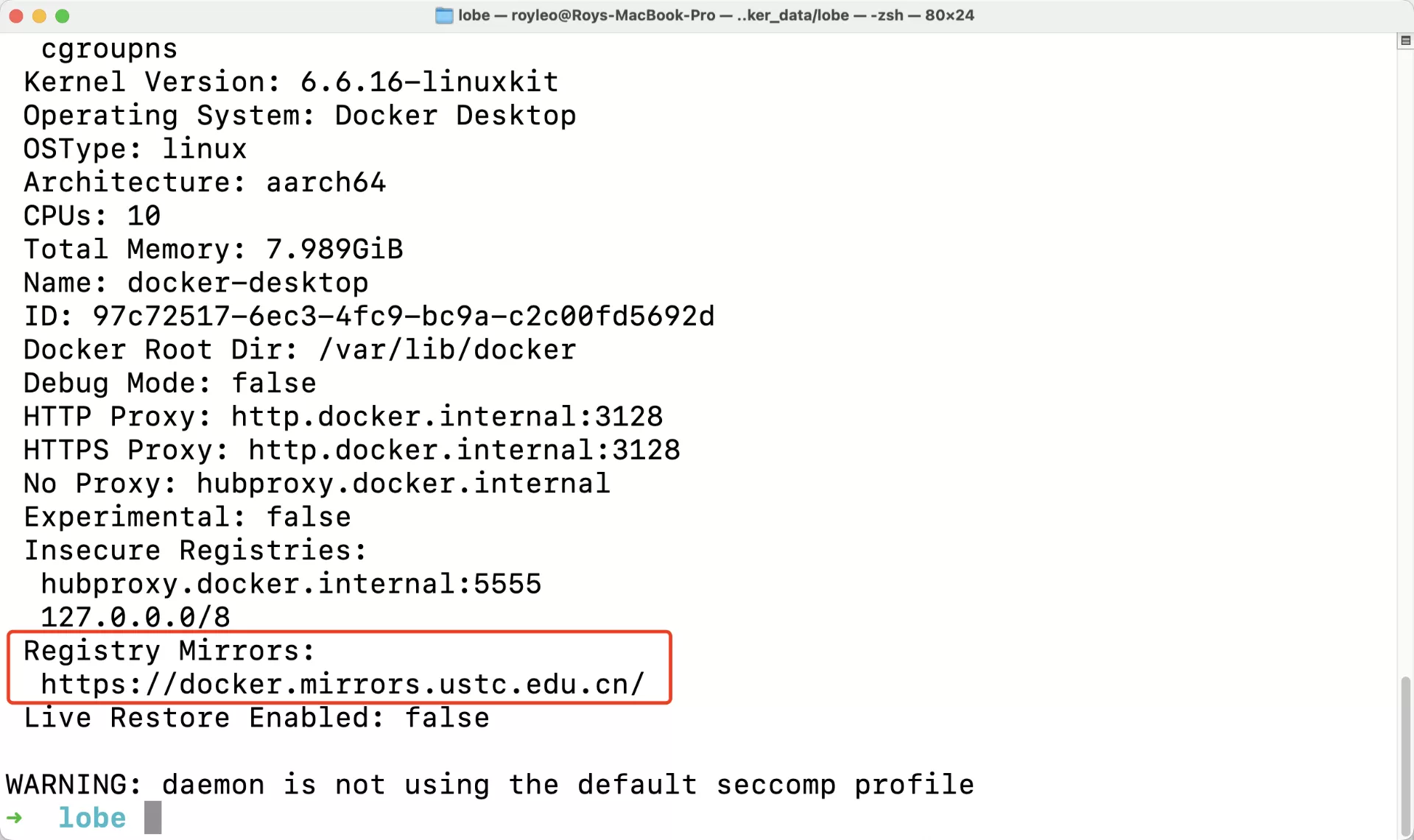
就可以了。
Lobechat配置
先在浏览器输入:http://127.0.0.1:11434

确保ollama在运行中。
再浏览器输入:http://127.0.0.1:11432

点击左上角小人头像:
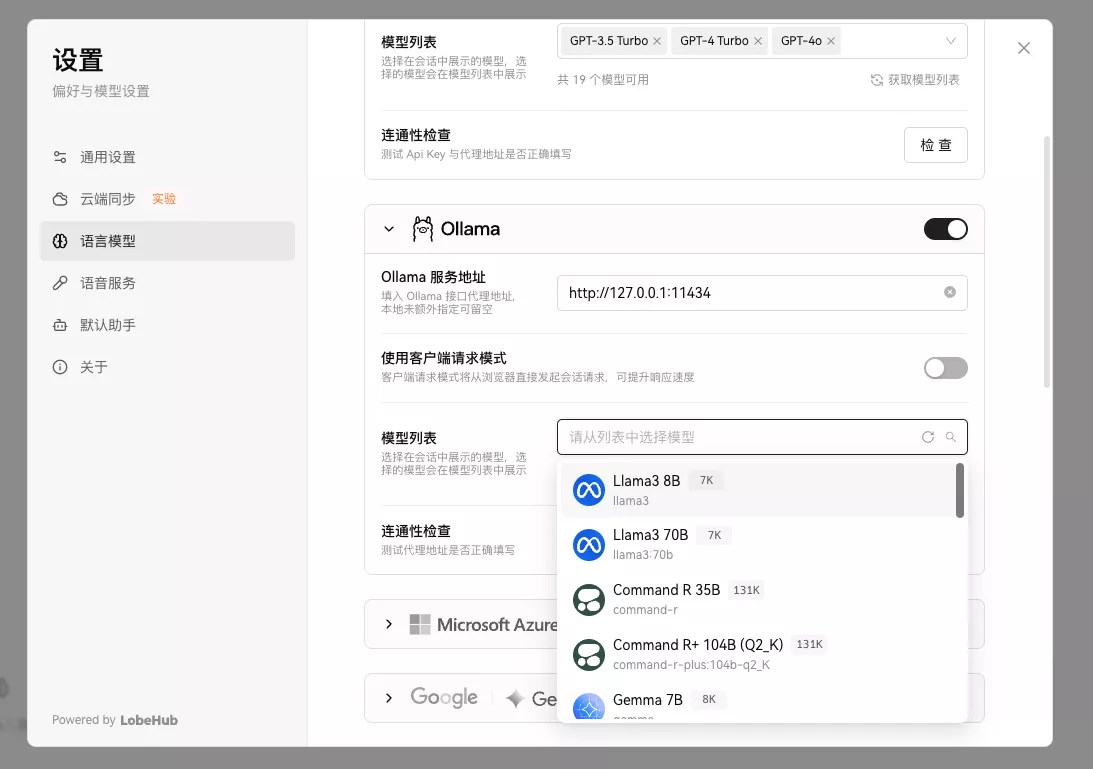
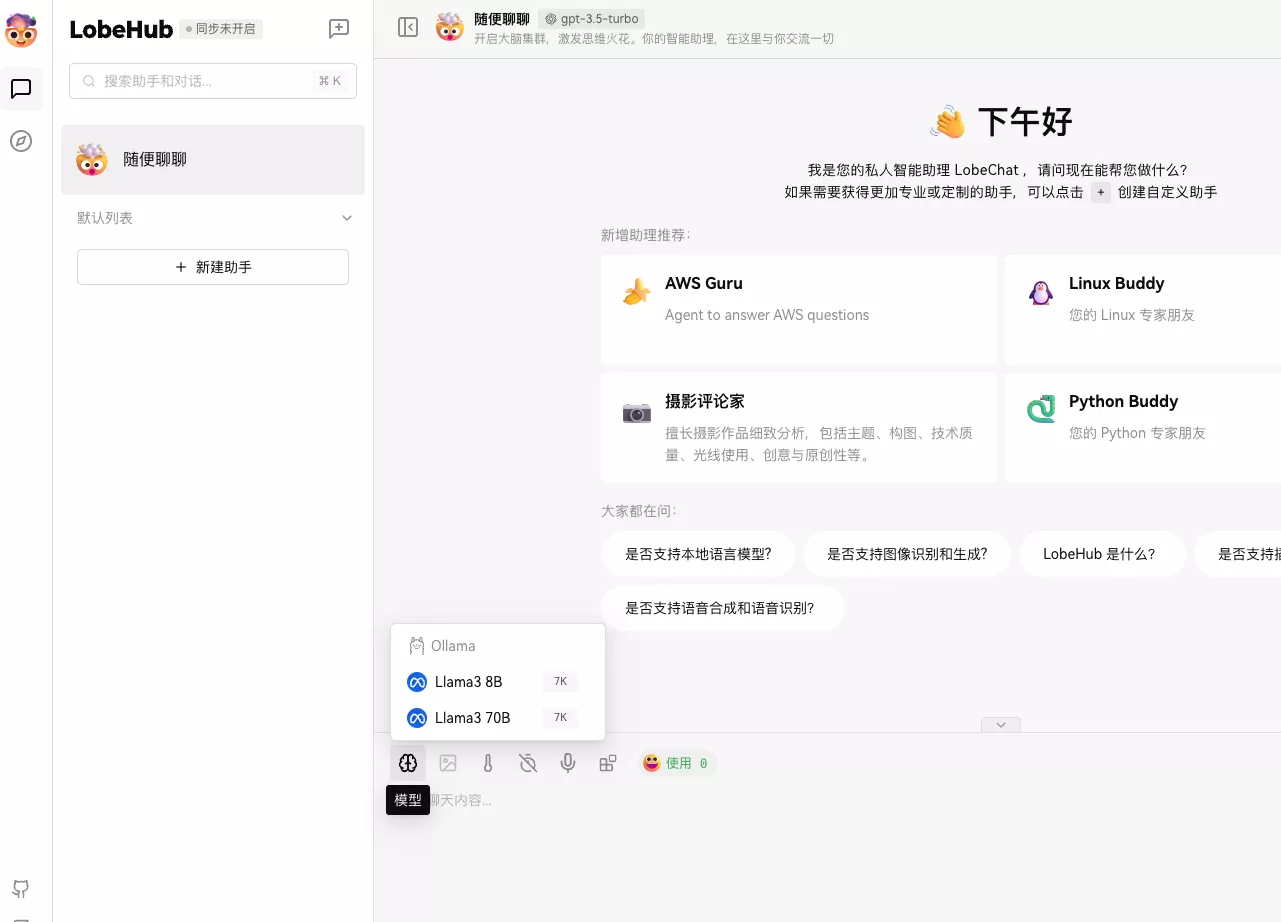
语言设置这边,把llama3 8B选上:
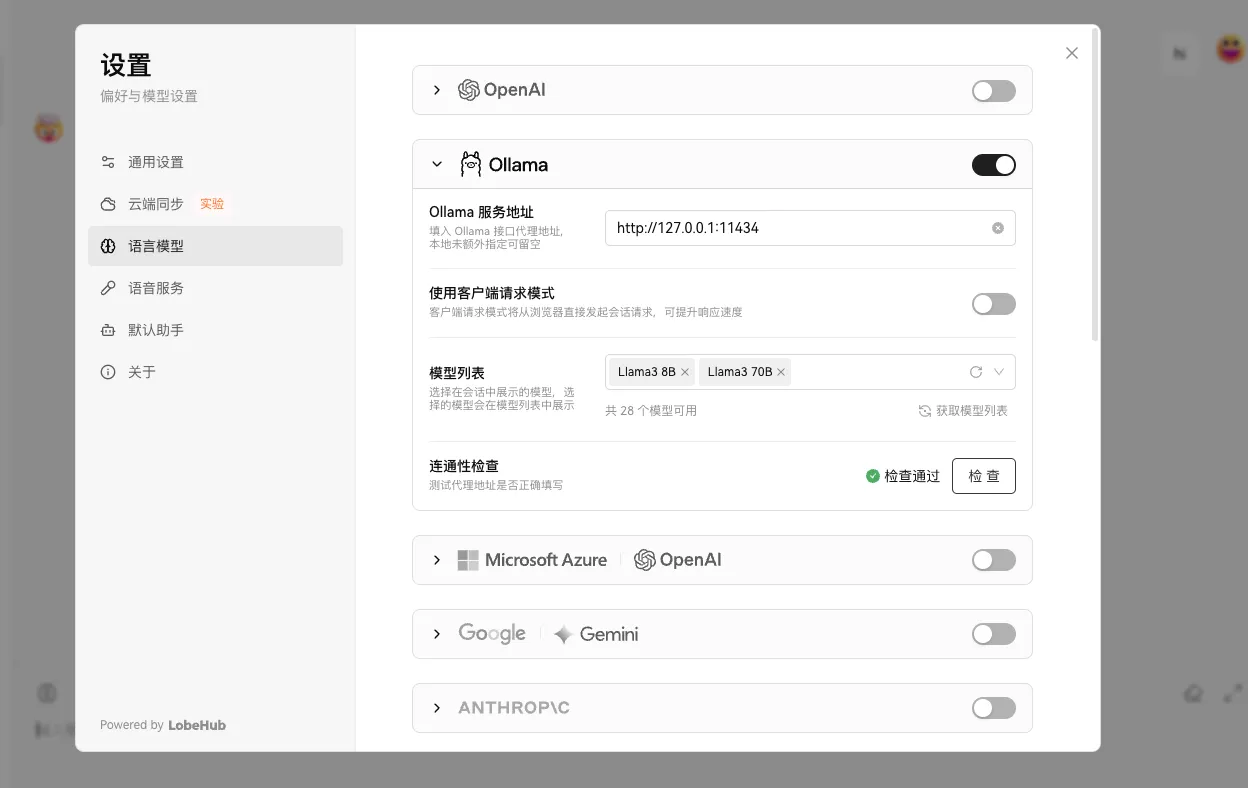
检查一下:
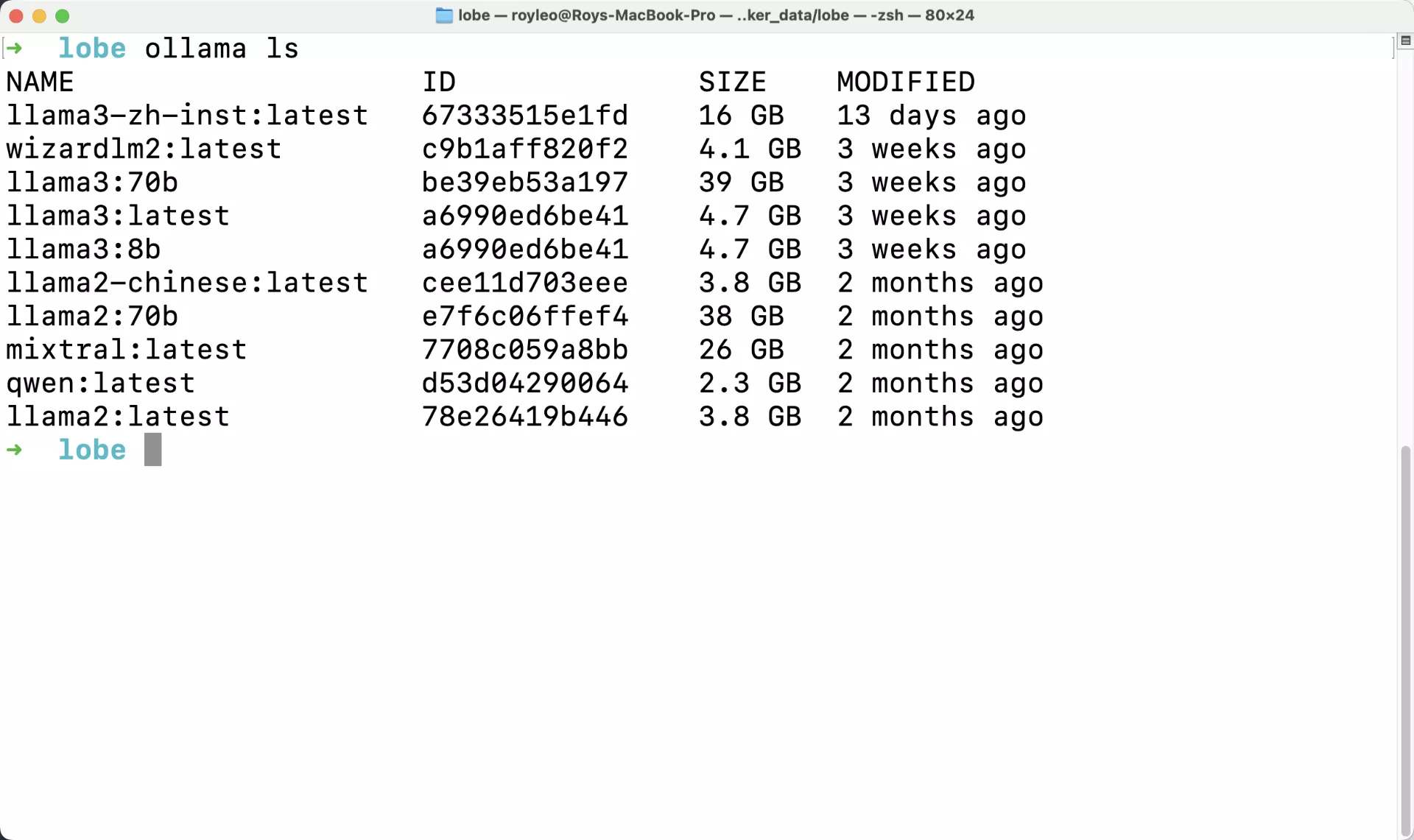
终端运行ollama ls
可以看到目前你下载的所有模型。
咕咕这边下载的比较多:
选择模型,就可以使用了:
记得这边输入一下密码:
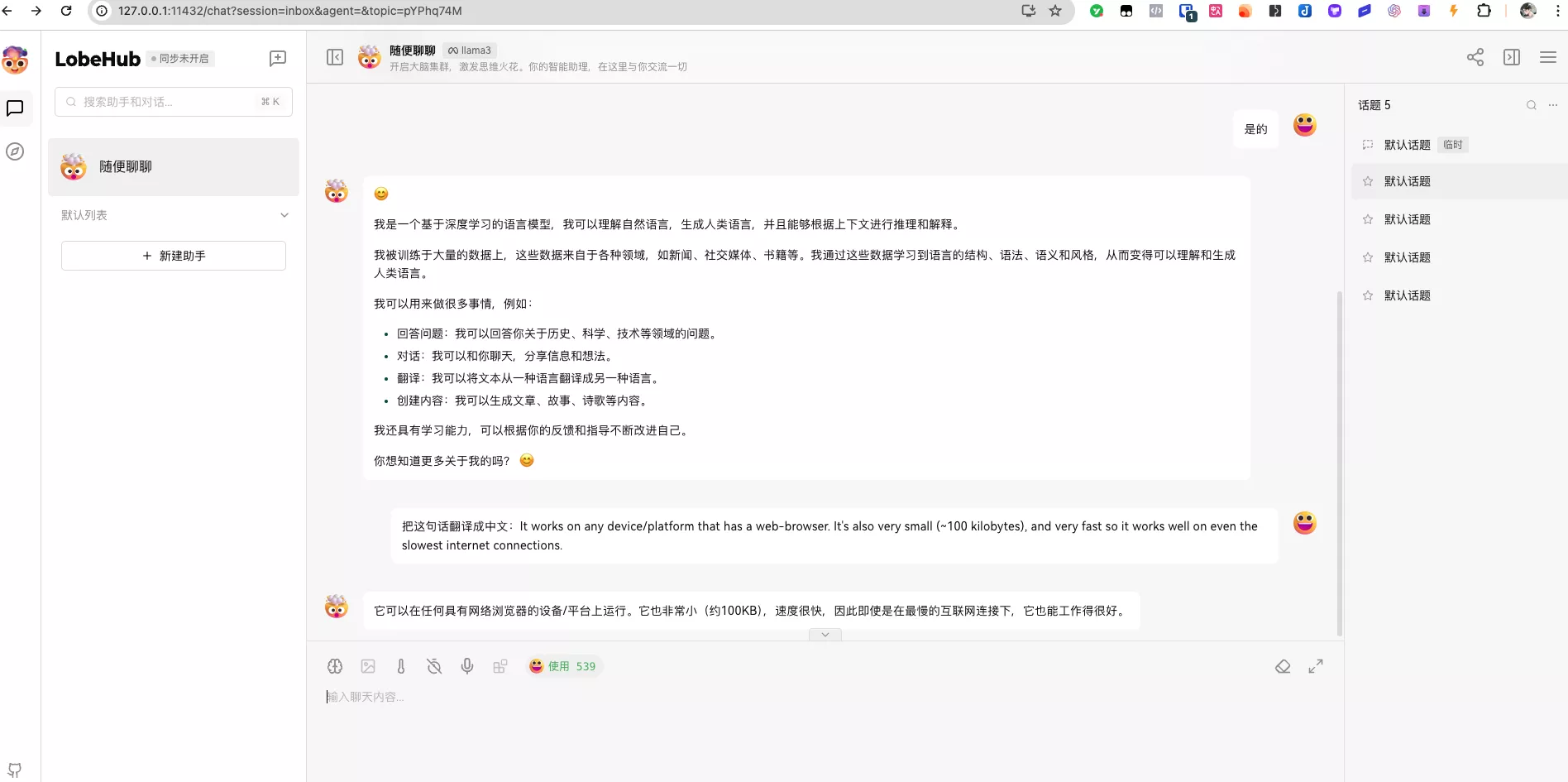
愉快地用起来吧,后续介绍如何利用这个搭配沉浸式翻译使用!


 glzjin's blog
glzjin's blog
文章评论